 شفا آنلاین>سلامت>اکنون، گروهی از محققان دانشگاه نیویورک اکتشافات
اساسی انجام دادهاند که به باز کردن این گره کمک میکند و از آن برای ساخت
فناوری بازسازی صدا استفاده کردند که صدای بیمارانی را که توانایی صحبت
کردن خود را از دست داده اند، به آنها بازگردانند.
شفا آنلاین>سلامت>اکنون، گروهی از محققان دانشگاه نیویورک اکتشافات
اساسی انجام دادهاند که به باز کردن این گره کمک میکند و از آن برای ساخت
فناوری بازسازی صدا استفاده کردند که صدای بیمارانی را که توانایی صحبت
کردن خود را از دست داده اند، به آنها بازگردانند.
به گزارش شفا آنلاین:این گروه به سرپرستی آدین فلینکر(Adeen Flinker)، دانشیار مهندسی بیومدیکال در دانشگاه تاندون نیویورک و دانشیار عصبشناسی در دانشکده پزشکی گروسمن نیویورک، و یائو وانگ(Yao Wang)، پروفسور مهندسی زیست پزشکی و مهندسی برق و رایانه در دانشگاه تاندون نیویورک برای بازسازی گفتار از سوابق مغز از شبکههای عصبی پیچیده استفاده کردند و سپس از آن بازسازی برای تجزیه و تحلیل فرآیندهایی که گفتار انسان را هدایت میکند، بهره بردند.
تولید گفتار در انسان یک رفتار پیچیده است که شامل کنترل فرمانهای حرکتی و همچنین پردازش بازخورد گفتار میشود. این فرآیندها نیازمند درگیری چندین شبکه مغزی پشت سر هم است. با این حال، تفکیک درجه و زمان به کار گیری قشر مغز برای کنترل حرکتی در مقابل پردازش حسی تولید شده توسط تولید گفتار دشوار بوده است.
در یک مقاله جدید، محققان با موفقیت فرآیندهای پیچیده بازخورد و پیشخورد را در طول تولید گفتار از هم متمایز کردند. این تیم با استفاده از یک یادگیری عمیق خلاقانه بر روی سوابق جراحی مغز و اعصاب انسان، از یک سنتزکننده گفتار متمایز مبتنی بر قانون برای رمزگشایی پارامترهای گفتار از سیگنالهای قشر مغز استفاده کردند.
محققان توانستند به طور دقیق سهم بازخورد و پیشخورد(feedforward) در تولید گفتار را تجزیه و تحلیل کنند.
محققان از این دیدگاه جدید برای توسعه پروتزهایی استفاده کردهاند که میتوانند فعالیت مغز را بخوانند و مستقیما آن را به گفتار رمزگشایی کنند. در حالی که بسیاری از محققان در حال کار بر روی توسعه چنین دستگاههایی هستند، نمونه اولیه دانشگاه نیویورک یک تفاوت اساسی دارد و آن این است که میتواند صدای بیمار را تنها با استفاده از مجموعه دادههای کوچکی از سوابق مغزی، به میزان قابل توجهی بازسازی کند.
نتیجه ممکن است این باشد که بیماران پس از از دست دادن صدایشان نه تنها موفق به بازگرداندن یک صدا شوند بلکه صدای خود را پس بگیرند. این به لطف یک شبکه عصبی عمیق است که فضای شنیداری نهفته را در نظر میگیرد و میتوان آن را تنها بر روی چند نمونه از صدای خود فرد، مانند ویدیوی که در آن صحبت کرده است، آموزش داد.
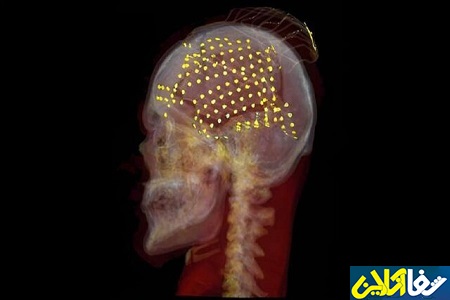
به منظور جمع آوری دادهها، محققان به گروهی از بیماران مبتلا به صرع مقاوم به درمان مراجعه کردند که در حال حاضر با دارو قابل درمان نیستند. این بیماران شبکهای از الکترودهای نوار مغزی را برای یک دوره یک هفتهای روی مغزشان کاشت کردند تا شرایط آنها را بررسی کند. آنها درک مهمی در مورد فعالیت مغز در طول عمل تولید گفتار در اختیار محققان قرار دادند.
محققان یافتههای جدید خود را در مقالهای در PNAS منتشر کردند./ایسنا

